Abstract
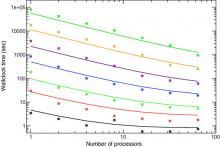
We describe source code level parallelization for the kira direct gravitational N-body integrator, the workhorse of the starlab production environment for simulating dense stellar systems. The parallelization strategy, called "j-parallelization", involves the partition of the computational domain by distributing all particles in the system among the available processors. Partial forces on the particles to be advanced are calculated in parallel by their parent processors, and are then summed in a final global operation. Once total forces are obtained, the computing elements proceed to the computation of their particle trajectories. We report the results of timing measurements on four different parallel computers, and compare them with theoretical predictions. The computers employ either a high-speed interconnect, a NUMA architecture to minimize the communication overhead or are distributed in a grid. The code scales well in the domain tested, which ranges from 1024 - 65536 stars on 1 - 128 processors, providing satisfactory speedup. Running the production environment on a grid becomes inefficient for more than 60 processors distributed across three sites.